Preprint · 2026
Coupled Local and Global World Models for Efficient First Order RL
Joseph Amigo*, Rooholla Khorrambakht*, Nicolas Mansard, Ludovic Righetti
* equal contribution
A decoupled first-order gradient (FoG) RL method that trains policies from scratch entirely inside a large-scale world model — also learned from scratch from real-world data — and deploys them zero-shot on the real robot.

Real-world tasks solved zero-shot by policies trained entirely inside our learned world models: Push-T with a tabletop manipulator (left), Ego-Centric Grasp and Lift with a G1 humanoid (centre), and Ego-Centric Push Cube with a Go2 quadruped (right).
Abstract
World models offer a promising avenue for capturing complex environment dynamics where simulators face challenges. However, large-scale world models required for complex real-world settings are computationally expensive to adopt in popular RL approaches. We introduce a novel first-order RL method that enables policy training via a decoupled first-order gradient (FoG): a large-scale world model generates accurate forward trajectories while a lightweight latent-space surrogate approximates its local dynamics for efficient gradient computation. This coupled local-and-global formulation allows high-fidelity forward dynamics alongside the computationally efficient differentiation needed for model-based RL. Across a range of real-world robotic tasks we demonstrate tractable RL and zero-shot deployment, with significantly better sample efficiency than PPO on a canonical real-world Push-T benchmark and similar gains on more complex ego-centric manipulation and grasping.
Method
We extend Decoupled forward-backward Model-based policy Optimization (DMO) to the simulator-free setting in image space. A pretrained large-scale world model (DIAMOND for Push-T, DreamerV4 for ego-centric tasks) acts as the global simulator surrogate. Alongside it, a lightweight Recurrent State-Space Model (RSSM) acts as the local low-dimensional latent dynamics that supplies stable, low-variance gradients without backpropagating through the heavy global model. Forward accuracy and backward tractability are optimised independently, opening the door to practical, efficient FoG-MBRL with large-scale pixel-space world models.
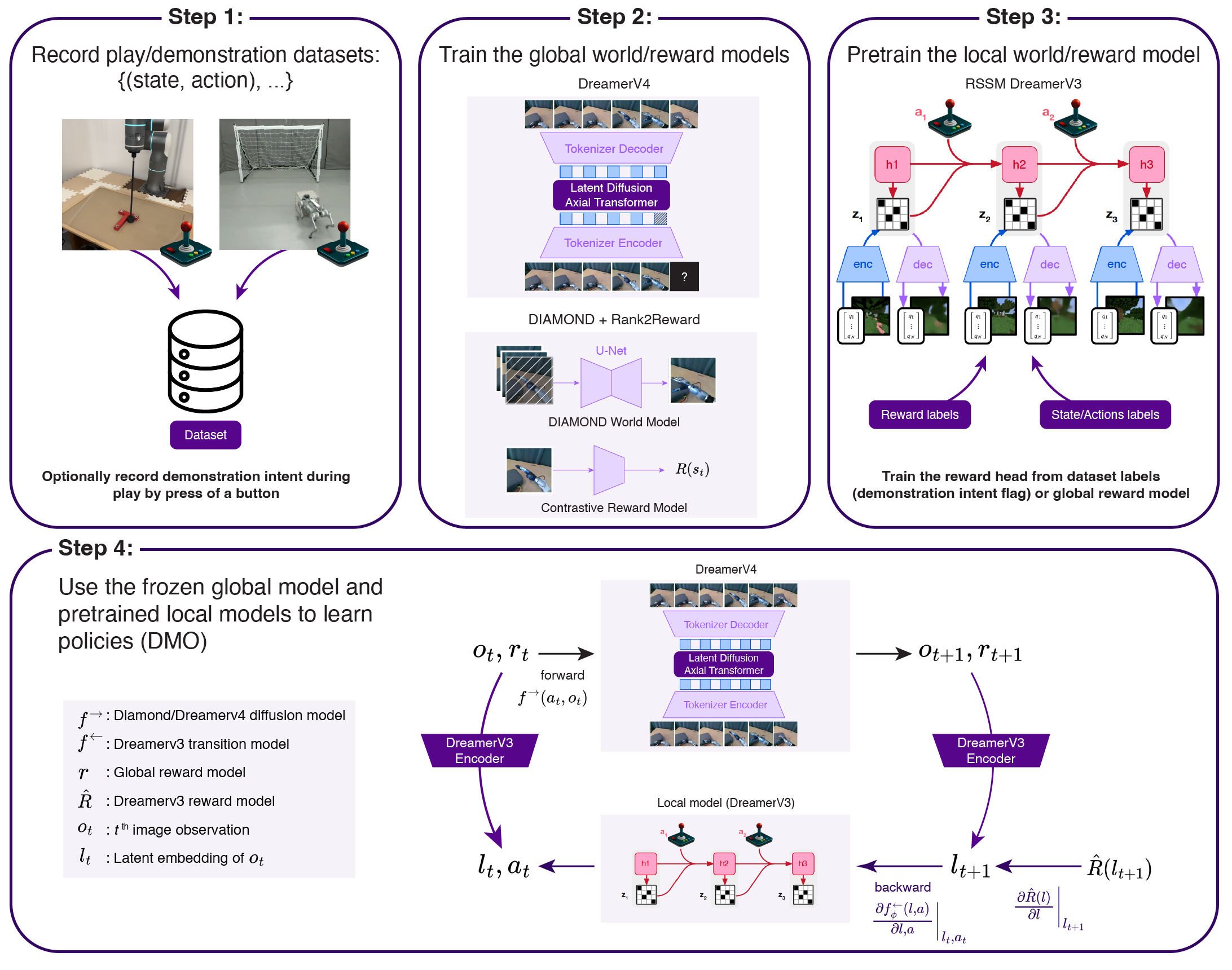
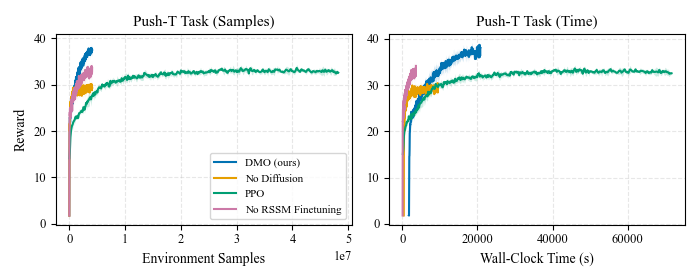
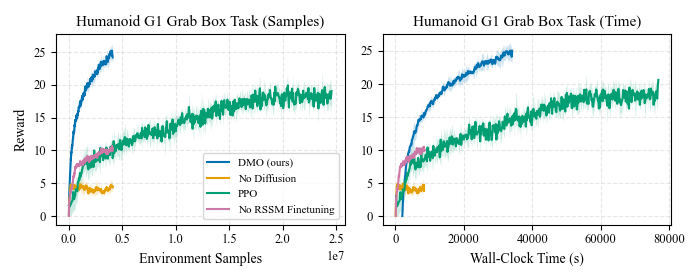
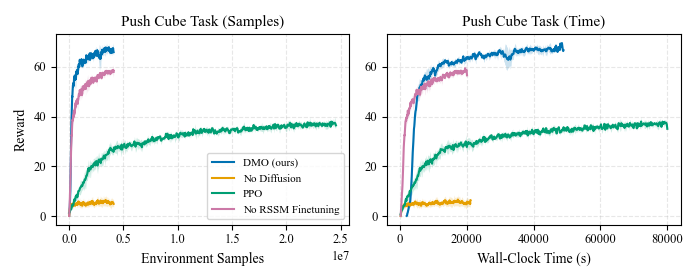
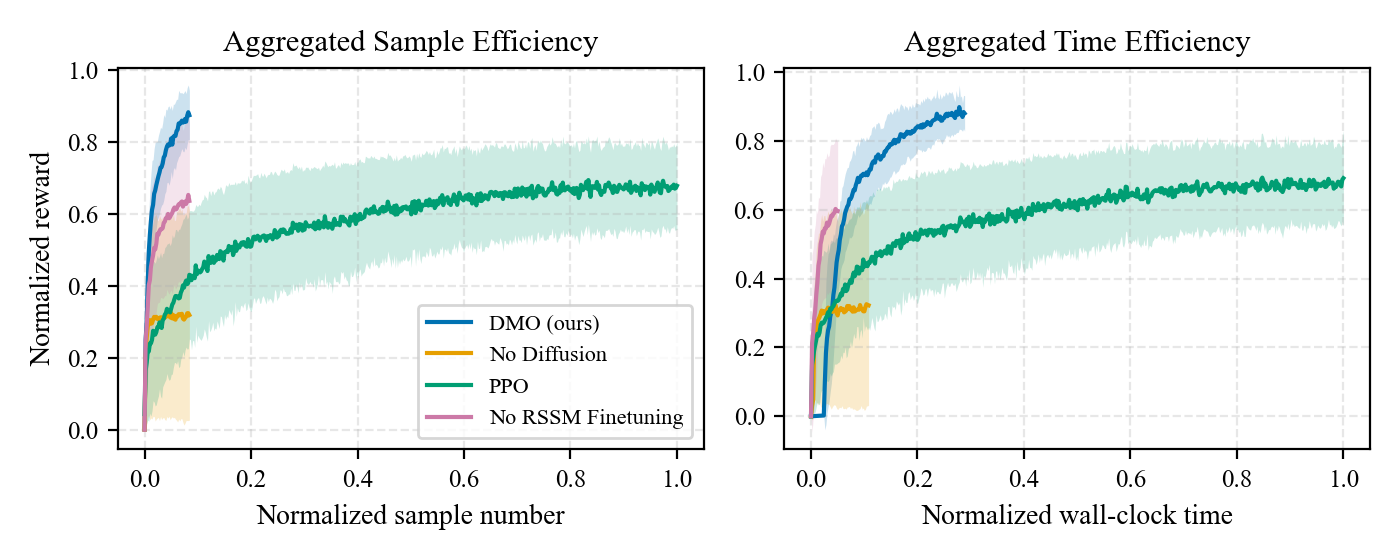
Sample efficiency
On Push-T we match or beat PPO with an order-of-magnitude fewer environment samples, and we see the same pattern on the more complex G1 ego-centric grasp-and-lift and Go2 ego-centric push-cube tasks. All curves are over 4 seeds. Click any figure to enlarge.
Real-robot rollouts
Policies trained entirely inside the learned world models, deployed zero-shot on hardware.
G1 humanoid · grasp & lift · ten successes in a row
The miniature inset (top-left) is exactly what the policy sees — a single head-mounted camera, with no wrist or external cameras. The third-person view is shown only for the viewer; the policy never has access to it. Only the grasp-and-lift motion is policy-driven: between trials a human teleoperator returns the box to the table, and the policy is restarted from scratch for the next attempt.
G1 humanoid · grab box — DMO (ours) vs ACT vs PPO
Scene 1
Scene 2
Scene 3
Push-T · tabletop manipulator
Go2 quadruped · what the policy sees — ego-centric partial observability
Left — a third-person view the policy never has access to, shown only for the viewer. Right — the policy's view: a narrow, ego-centric camera feed, all the policy ever receives. When the cube falls outside the narrow field of view the agent must remember where it last saw it and actively search — illustrating how partially observable this task is.
Go2 quadruped · ego-centric push-cube — DMO (ours) vs PPO vs BC (ACT)
Scene 1 — going straight to the goal
Scene 2 — discovery behaviour when the cube is initially out of view
Scene 3 — same task with a different low-level locomotion policy
World-model fidelity
A side-by-side rollout on the G1 humanoid grasp-and-lift task lets us inspect how the global diffusion world model and the lightweight local RSSM each track the real trajectory over a six-second horizon. The global model preserves visual fidelity and contact dynamics long after the local model loses high-frequency detail — which is exactly why we keep the global model in the forward pass and reserve the local model for cheap backward gradients.
Real camera
Local · DreamerV3 RSSM
Global · DreamerV4 diffusion
Imagined rollouts
A selection of short clips extracted from a single long interactive teleoperation episode run entirely inside the learned world model. Each clip is at the model's native 256×256 resolution; the scalar overlay on every clip is the per-step reward predicted by the world model's own reward head.
G1 humanoid · world-model rollouts · reward-head overlay
Patching world-model exploits
When training a high-reward RL policy entirely inside a learned world model, the policy inevitably finds physical hallucinations — frames where the world model breaks its own physics to maximise reward. Our pipeline deploys those exploit policies on the real robot to harvest targeted patching data, then fine-tunes the world model on it. The clips below show the same exploit policy rolled out on the original and the patched model — the hallucination disappears.
Exploit 1 — the box teleports into the grasp
Exploit 2 — the box is dragged by an invisible force
BibTeX
@misc{amigo2026coupledlocalglobalworld,
title={Coupled Local and Global World Models for Efficient First Order RL},
author={Joseph Amigo and Rooholla Khorrambakht and Nicolas Mansard and Ludovic Righetti},
year={2026},
eprint={2602.06219},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2602.06219},
}